JSTOR 数据库的实验室推出一项Beta版的查找工具—“ Text Analyzer”,能自动判读、分析一段文章的关键字及其权重,并查找出 JSTOR 中的相关文献。由JSTOR主页的Tools选单,进入使用Text Analyzer。
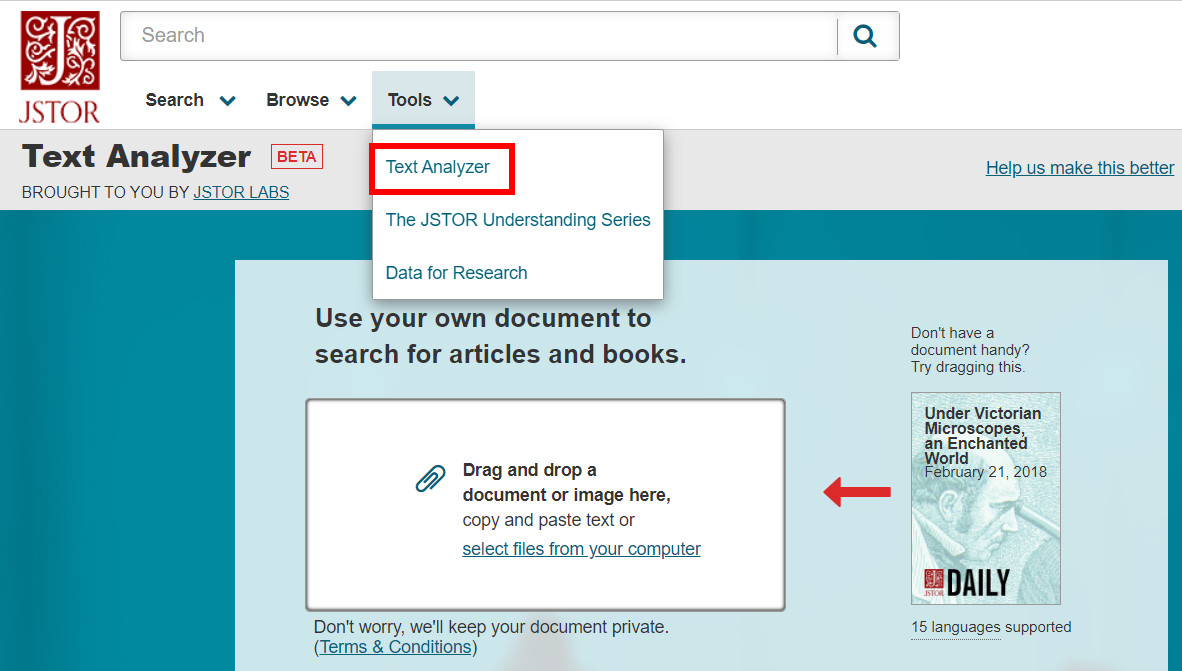
您可以通过拖曳、剪贴或上载的方式,提供一段文章、一个文件、一串URL链接或一页文字截图,它就会开始进行判读及分析。
自2018年1月起,除了英文以外,也支持另外14种语文的判读与分析,包括中文(简体)在内。

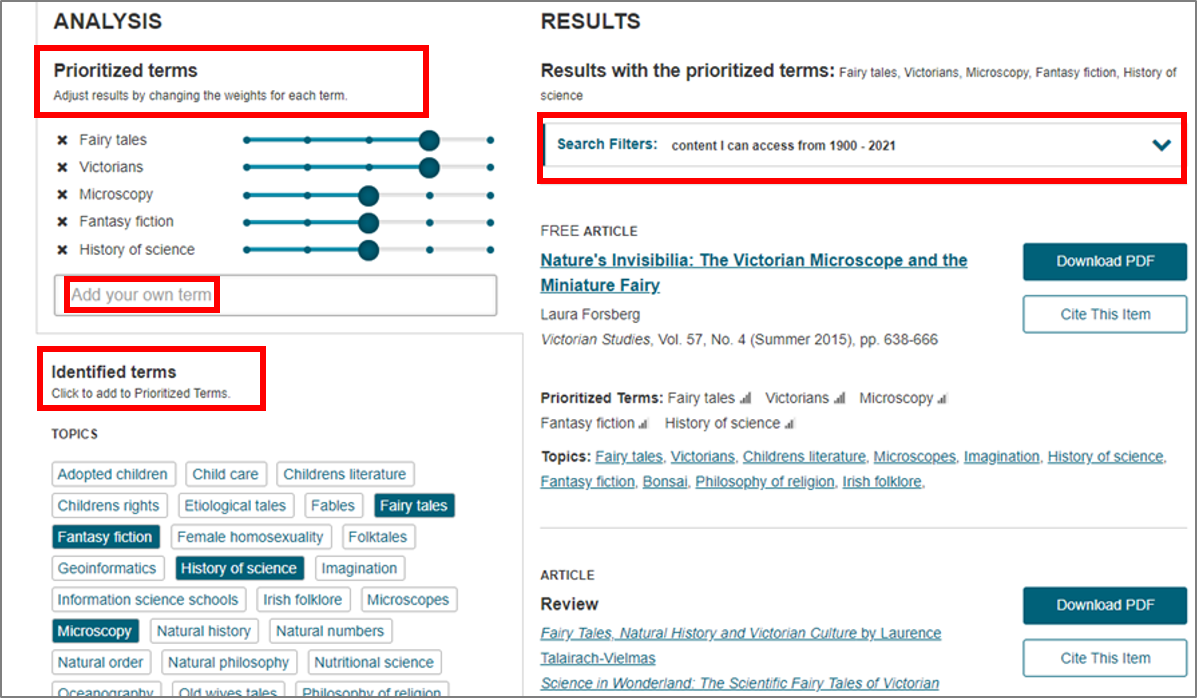
Text Analyzer会就您所提供的全文,自动寻找主要的概念与词汇,设置为Prioritized Terms,作为查找JSTOR数据库中相关文献的关键字,从而产生查找结果。

针对这些自动产生的 Prioritized Terms,您可以手动调整其权重、删除或添加关键字,也可以从画面左下方Identified Terms选取其他相关词汇,加入 Prioritized Terms 行列。只要进行任何手动调整,画面右方的查找结果就会跟著改变。
此外,如果您是利用手机进入 JSTOR 使用 Text Analyzer功能,画面会多出照相机图标,表示您也可拍摄文章截图来进行搜索。

Text Analyzer可以接受的文件格式包括:csv, doc, docx, gif, htm, html, jpg, jpeg, json, pdf, png, pptx, rtf, tif (tiff), txt, xlsx。若遇其他文件格式,您可以自行剪贴全文内容到查找框进行搜索。
依据其使用说明,JSTOR 并不会储存您所上传的数据。
下次当您构思论文或撰写报告时,不妨试试看 JSTOR 数据库的Text Analyzer,寻找延伸数据!
By Ya-tzu Liu (2018/2/7, 2021/9/7 updated)